Please read everything found on the mainpage before continuing; disclaimer and all.
![]()




![]()








Install these libraries onto the virtual environment.
%%capture
!pip install geopandas
!pip install VitalSigns
from VitalSigns.acsDownload import retrieve_acs_data
%load_ext autoreload
%autoreload 2
ls
!nbdev_update_lib -h
ls
!nbdev_build_lib
!nbdev_update_lib
# !nbdev_build_lib --fname './notebooks/02_Merge_Data.ipynb'
Our example will merge two simple datasets; pulling CSA names using tract ID's.
The First dataset will be obtained from the Census' ACS 5-year serveys.
Functions used to obtain this data were obtained from Tutorial 0) ACS: Explore and Download.
The Second dataset is from a publicly accessible link
We will use the function we created in our last tutorial to download the data!
# Change these values in the cell below using different geographic reference codes will change those parameters
tract = '*'
county = '510'
state = '24'
# Specify the download parameters the function will receieve here
tableId = 'B19001'
year = '17'
saveAcs = False
df = retrieve_acs_data(state, county, tract, tableId, year, saveAcs)
df.head()
Spatial data can be attained by using the 2010 Census Tract Shapefile Picking Tool or search their website for Tiger/Line Shapefiles
The core TIGER/Line Files and Shapefiles do not include demographic data, but they do contain geographic entity codes (GEOIDs) that can be linked to the Census Bureau’s demographic data, available on data.census.gov.-census.gov
For this example, we will simply pull a local dataset containing columns labeling tracts within Baltimore City and their corresponding CSA (Community Statistical Area). Typically, we use this dataset internally as a "crosswalk" where-upon a succesfull merge using the tract column, will be merged with a 3rd dataset along it's CSA column.
# !wget https://raw.githubusercontent.com/bniajfi/bniajfi/main/CSA-to-Tract-2010.csv
or, Alternately
# !curl https://raw.githubusercontent.com/bniajfi/bniajfi/main/CSA-to-Tract-2010.csv > CSA-to-Tract-2010.csv
print('Boundaries Example:CSA-to-Tract-2010.csv')
# Our Example dataset contains Polygon Geometry information.
# We want to merge this over to our principle dataset.
# we will grab it by matching on either CSA or Tract
# The url listed below is public.
print('Tract 2 CSA Crosswalk : CSA-to-Tract-2010.csv')
from dataplay.intaker import Intake
crosswalk = Intake.getData( 'https://raw.githubusercontent.com/bniajfi/bniajfi/main/CSA-to-Tract-2010.csv' )
crosswalk.head()
crosswalk.columns
The following picture does nothing important but serves as a friendly reminder of the 4 basic join types.
- Left - returns all left records, only includes the right record if it has a match
- Right - Returns all right records, only includes the left record if it has a match
- Full - Returns all records regardless of keys matching
- Inner - Returns only records where a key match
Get Columns from both datasets to match on
You can get these values from the column values above.
Our Examples will work with the prompted values
print( 'Princpal Columns ' + str(df.columns) + '')
left_on = input("Left on crosswalk column: ('tract') \n" ) or "tract"
print(' \n ');
print( 'Crosswalk Columns ' + str(crosswalk.columns) + '')
right_on = input("Right on crosswalk column: ('TRACTCE10') \n" ) or "TRACTCE10"
Specify how the merge will be performed
We will perform a left merge in this example.
It will return our Principal dataset with columns from the second dataset appended to records where their specified columns match.
how = input("How: (‘left’, ‘right’, ‘outer’, ‘inner’) " ) or 'outer'
Actually perfrom the merge
merged_df = pd.merge(df, crosswalk, left_on=left_on, right_on=right_on, how=how)
merged_df = merged_df.drop(left_on, axis=1)
merged_df.head()
As you can see, our Census data will now have a CSA appended to it.
# outFile = input("Please enter the new Filename to save the data to ('acs_csa_merge_test': " )
# merged_df.to_csv(outFile+'.csv', quoting=csv.QUOTE_ALL)
flag = input("Enter a URL? If not ACS data will be used. (Y/N): " ) or "N"
if (flag == 'y' or flag == 'Y'):
left_df = Intake.getData( input("Please enter the location of your Left file: " ) )
else:
tract = input("Please enter tract id (*): " ) or "*"
county = input("Please enter county id (510): " ) or "510"
state = input("Please enter state id (24): " ) or "24"
tableId = input("Please enter acs table id (B19001): " ) or "B19001"
year = input("Please enter acs year (18): " ) or "18"
saveAcs = input("Save ACS? (Y/N): " ) or "N"
left_df = retrieve_acs_data(state, county, tract, tableId, year, saveAcs)
print('right_df Example: CSA-to-Tract-2010.csv')
right_df = Intake.getData( input("Please enter the location of your right_df file: " ) or 'https://raw.githubusercontent.com/bniajfi/bniajfi/main/CSA-to-Tract-2010.csv' )
print( 'Left Columns ' + str(left_df.columns))
print( '\n ')
print( 'right_df Columns ' + str(right_df.columns) + '\n')
left_on = input("Left on: " ) or 'tract'
right_on = input("Right on: " ) or 'TRACTCE10'
how = input("How: (‘left’, ‘right’, ‘outer’, ‘inner’) " ) or 'outer'
merged_df = pd.merge(left_df, right_df, left_on=left_on, right_on=right_on, how=how)
merged_df = merged_df.drop(left_on, axis=1)
# Save the data
# Save the data
saveFile = input("Save File ('Y' or 'N'): ") or 'N'
if saveFile == 'Y' or saveFile == 'y':
outFile = input("Saved Filename (Do not include the file extension ): ")
merged_df.to_csv(outFile+'.csv', quoting=csv.QUOTE_ALL);
merged_df.head(1)
For this next example to work, we will need to import hypothetical csv files
Intro
The following Python function is a bulked out version of the previous notes.
- It contains everything from the tutorial plus more.
- It can be imported and used in future projects or stand alone.
Description: add columns of data from a foreign dataset into a primary dataset along set parameters.
Purpose: Makes Merging datasets simple
Services
- Merge two datasets without a crosswalk
- Merge two datasets with a crosswalk
Input(s):
- Dataset url
- Crosswalk Url
- Right On
- Left On
- How
- New Filename
Output: File
How it works:
- Read in datasets
Perform Merge
If the 'how' parameter is equal to ['left', 'right', 'outer', 'inner']
- then a merge will be performed.
- If a column name is provided in the 'how' parameter
- then that single column will be pulled from the right dataset as a new column in the left_ds.
Diagram the mergeDatasets()
%%html
<img src="https://bniajfi.org/images/mermaid/class_diagram_merge_datasets.PNG">

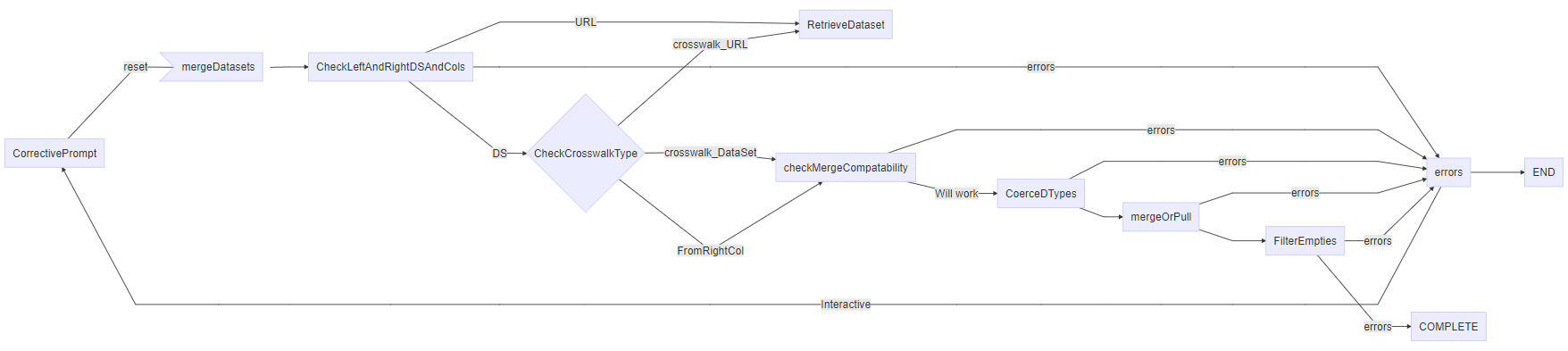
mergeDatasets Flow Chart
%%html
<img src="https://bniajfi.org/images/mermaid/flow_chart_merge_datasets.PNG">
Gannt Chart mergeDatasets()
%%html
<img src="https://bniajfi.org/images/mermaid/gannt_chart_merge_datasets.PNG">

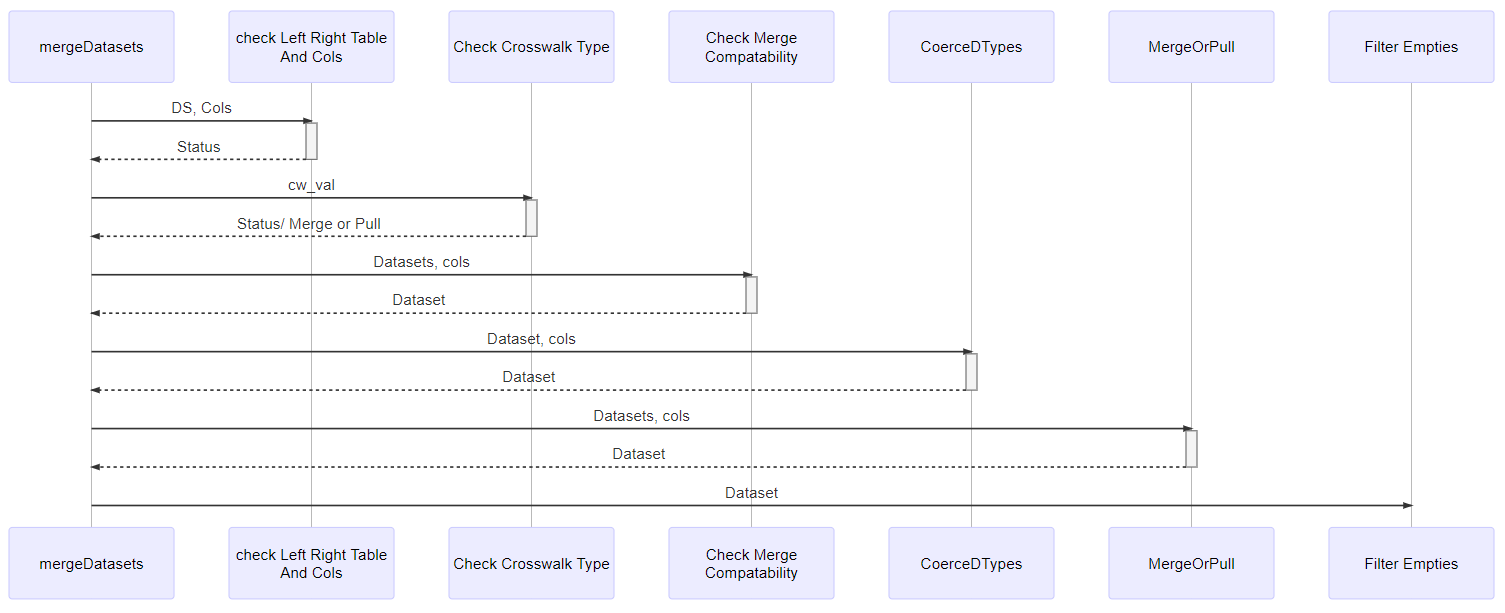
Sequence Diagram mergeDatasets()
%%html
<img src="https://bniajfi.org/images/mermaid/sequence_diagram_merge_datasets.PNG">
# from dataplay.geoms import readInGeometryData
# Hhchpov = Intake.getData("https://services1.arcgis.com/mVFRs7NF4iFitgbY/ArcGIS/rest/services/Hhchpov/FeatureServer/0/query?where=1%3D1&outFields=*&returnGeometry=true&f=pgeojson", interactive=True)
# Hhchpov = Hhchpov[['CSA2010', 'hhchpov15', 'hhchpov16', 'hhchpov17', 'hhchpov18']]
left_ds = "https://services1.arcgis.com/mVFRs7NF4iFitgbY/ArcGIS/rest/services/Hhchpov/FeatureServer/0/query?where=1%3D1&outFields=*&returnGeometry=true&f=pgeojson"
left_col = 'CSA2010'
# Table: Household Poverty
# Hhpov = Intake.getData("https://services1.arcgis.com/mVFRs7NF4iFitgbY/ArcGIS/rest/services/Hhpov/FeatureServer/0/query?where=1%3D1&outFields=*&returnGeometry=true&f=pgeojson", interactive=True)
# Hhpov = Hhpov[['CSA2010', 'hhpov15', 'hhpov16', 'hhpov17', 'hhpov18']]
right_ds = "https://services1.arcgis.com/mVFRs7NF4iFitgbY/ArcGIS/rest/services/Hhpov/FeatureServer/0/query?where=1%3D1&outFields=*&returnGeometry=true&f=pgeojson"
right_col='CSA2010'
merge_how = 'outer'
interactive = False
merged_df = mergeDatasets(left_ds=left_ds, right_ds=right_ds, crosswalk_ds='no',
left_col=left_col, right_col=right_col,
crosswalk_left_col = False, crosswalk_right_col = False,
merge_how=merge_how, # left right or columnname to retrieve
interactive=interactive)
merged_df.head()
# Change these values in the cell below using different geographic reference codes will change those parameters
tract = '*'
county = '510' # '059' # 153 '510'
state = '24' #51
# Specify the download parameters the function will receieve here
tableId = 'B19049' # 'B19001'
year = '17'
saveAcs = False
import pandas as pd
import IPython
# from IPython.core.display import HTML
IPython.core.display.HTML("<style>.rendered_html th {max-width: 200px; overflow:auto;}</style>")
# state, county, tract, tableId, year, saveOriginal, save
left_df = retrieve_acs_data(state, county, tract, tableId, year, saveAcs)
left_df.head(1)
# Columns: Address(es), Census Tract
left_ds = left_df
left_col = 'tract'
# Table: Crosswalk Census Communities
# 'TRACT2010', 'GEOID2010', 'CSA2010'
crosswalk_ds = 'https://raw.githubusercontent.com/bniajfi/bniajfi/main/CSA-to-Tract-2010.csv'
crosswalk_left_col = 'TRACTCE10'
crosswalk_right_col = 'CSA2010'
# Table:
right_ds = 'https://services1.arcgis.com/mVFRs7NF4iFitgbY/ArcGIS/rest/services/Hhpov/FeatureServer/0/query?where=1%3D1&outFields=*&returnGeometry=true&f=pgeojson'
right_col = 'CSA2010'
interactive = False
merge_how = 'outer'
merged_df_geom = mergeDatasets(left_ds=left_ds, right_ds=right_ds, crosswalk_ds=crosswalk_ds,
left_col=left_col, right_col=right_col,
crosswalk_left_col = crosswalk_left_col, crosswalk_right_col = crosswalk_right_col,
merge_how=merge_how, # left right or columnname to retrieve
interactive=interactive)
merged_df_geom.head()
Here we can save the data so that it may be used in later tutorials.
# merged_df.to_csv(string+'.csv', encoding="utf-8", index=False, quoting=csv.QUOTE_ALL)
mergeDatasets( ).head(1)
mergeDatasets().head(1)